By Sterling Cloud Architect Nathan Bennett
From empty shelves in the grocery store to the lack of vehicles in the local car dealership to the massive gap in the production and distribution of computer chips, COVID-19’s disruptions to the supply chain continues. (The pandemic wasn’t the only disrupter, of course. Another was the gargantuan container ship that got stuck for six days in the Suez Canal and held up an estimated 9 ½ billion dollars of goods per day, adding to the overall backup.)
In 2020, we thought the supply issues would be a brief — if big — inconvenience. Now well into 2021, we’re seeing that disruptions around the globe can and have caused serious issues for the rest of us. None of us are singularly dependent on ourselves or on any one geopolitical entity. We are all dependent on many, and they are dependent on us.
This supply-chain situation is not showing indications of resolving for the next year or more. Here at Sterling, we too are experiencing the fallout from all of this: from our providers announcing long waits for laptops, to the changes we will need to perform to find the proper components for our customers. We’ve been adapting and dancing to the beat of this new drum for a while now. In fact, we’ve learned some good lessons from this situation (which we are all in) and want to share some ways you too can work around these issues.
Five ways to work around the chip shortage
- Get your order in asap
Priority zero at this point is to get your orders in now. If you need an influx of laptops or servers, don’t wait. Think of this as getting in line for what you need before you need them. For me, queues are a big sign of new times. I was one of the few people who were able to secure a PlayStation 5 on launch. It meant 24 hours of no sleep, and I did it by research, action, and automation. It started at 11:00 p.m. the day before. I learned that the launch of the consoles was going to be done across multiple vendors during the early morning, so I had multiple tabs open, all to the proper segments. I knew APIs and had scripted multiple connections via http calls and then ran multiple refreshes across the tabs throughout the night. At 4:00 a.m. I got the first PlayStation 5 through a regular update at Target. At 10 a.m. I was able to get another for my brother, which then fell through, with the notification that the order would not be filled. Then at 6:00 p.m., I was able to snag another through PlayStation’s website, which put everyone into a queue in which each had to wait their turn to get to the front of the line before they found out if they would get a chance to purchase the console.
I saw that screen for a very long time.
But I followed instructions, and my brother got his PlayStation 5 that day. Long story about a silly console, sure, but the chips that run in that console are in many other consoles, in GPUs (graphic processing units), and even some Mac computers. The amount of time and effort to find those resources when I was trying to get them was intense in comparison to other days. This is where we are in the current crisis. The chip shortage is particularly painful because each chip has multiple uses. So, it is critical that you get into the queue as soon as possible. Putting in your order immediately allows you to be prepped before an emergency or critical application load hits your environment.
- Verify that everything is running ‘hot’
Let us investigate running CPU cycles in a virtualized environment. This means that adding new CPUs to a virtual machine won’t necessarily make it faster, and in a lot of cases will make it slower. Hypervisors run best when being utilized at 80%. This is normally referred to as “running hot.” This way, the CPU cycles are keeping up with the workload needs. To quickly explain how this works, we can use the analogy of dining out: A group of five diners go into a restaurant and ask for a table. While waiting, they see a couple of couples — two “tables of two” — get seated ahead of them. This often occurs because a table of two is easier to seat, with the tables available. With CPU cycles it’s very much the same.
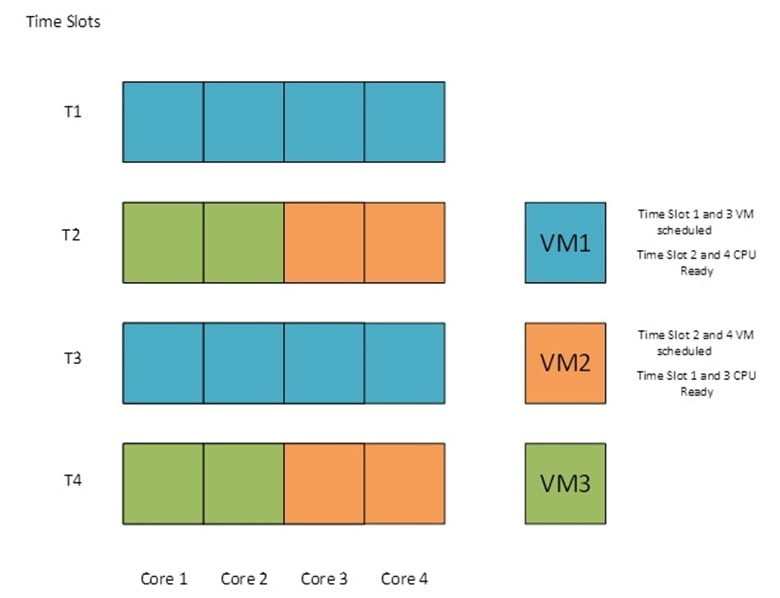
Example of CPU cycles with four cores and three VMs
Verifying that you are running hot in a virtual environment is known as “right-sizing” or making sure each VM is utilizing the right size of CPUs that it needs. Each CPU cycle, the hypervisor hands out as many CPU cores as it has per cycle. This means if your virtual machine needs a large number of CPUs, you may have to wait multiple cycles before you get your resources. So, even though that virtual machine has a ton of CPUs attached to it, it’s not able to run any faster because it’s having to wait more cycles to get the resources than it would need. To do this you need to verify what usage your workloads are pulling and set the resources accordingly.
Outside of doing this manually, vRealize Operations is a great tool to help verify your environment is running hot. What vRealize Operations performs is the basic logging tasks to verify the needs of the virtual workloads. It has built-in functionality to right-size your environment and make it run hot (or, to put it a different way, to ensure you are using best practices to utilize your resources at their capacity).
- Utilize storage in multiple places
The next step to survival during this supply crisis is the expansion of your storage, or, I should say, using your storage wisely. Though storage devices may not be hit as hard as other components, it is a good idea to make sure you are utilizing multiple storage endpoints in your environment. What fills up your storage? Which cold-storage files don’t you need, or don’t you need to store locally? Local storage is great for quick and usable data that can be pulled/pushed from application to application. However, what about your cold data? What are you utilizing for logging? Some environments store large amounts of data locally for log files. These can be exported to a cloud-logging solution that can then be exported into a dashboard where the data can be consumed. What about distributed file services? How many file servers do you have in the environment?
What if you could take those file servers and turn them into hot-caches that push your colder data into the cloud while keeping the hotter data local? This is exactly what tools like AWS FSx and Azure File Sync do. AWS FSx and Azure File Sync retain the needed metadata within your data, which keeps settings for each share and each file, while also pulling your colder data and pushing it into file shares in the cloud. If you ever used a cloud-based storage on your laptop — like Apple iCloud, Google Drive, or Microsoft OneDrive — they migrate your files back and forth, to and from the cloud, to make sure the data you need is local, and the data you’re not using is on the cloud.
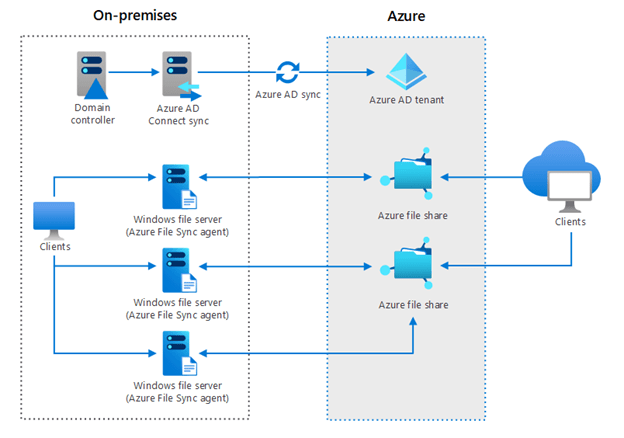
Azure File Sync on and off cloud
- Check native cloud
Have you checked the native cloud space? This is where you can expand your cloud into things that aren’t local. The first step is to connect your private location to the cloud. This is done via either a VPN or a direct connection that allows you to transfer data securely to and from the cloud. Once you have created a connection to the native cloud of your choice, you can start looking into the solutions the cloud allows that bypass your local resources and merges them into the cloud resources.
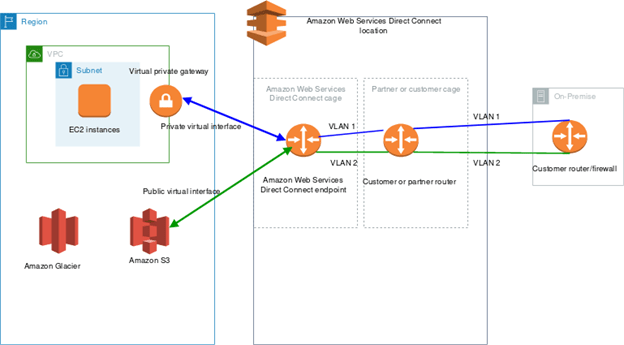
AWS Direct Connect
This could be a different extension of the logging services we talked about previously. Perhaps it is also utilizing different virtualization for infrastructure or merging that SQL instance that’s sucking up resources deployed natively in a highly available and resilient way. All these solutions in the cloud extend your private cloud into multiple other services that free up your private cloud resources and use those already existing in the cloud.
- Doing more with less
Finally, when looking to do more with less, the question always arises, “How can you automate this?” I’m sure this question sounds strange when dealing with the inability to get physical microchips. When you can automate infrastructure, especially via self-service, you gain the ability to treat all infrastructure the same as disposable plastic cups. When you see machines as disposable entities, you can do awesome things with a footprint in the public and the private cloud. Perhaps you will start with understanding what needs to run, when it needs to run, and how to kick it off. In the world of DevOps the understanding of kicking off automation to build a machine for additional computation allows machines to fill in when needed, but not hang around and use resources after use.
Auto-scaling in the public cloud
This is normally used with spot instances within the public cloud space to utilize short-term use-cases. When we view resources in short-term units and not the constant need from day to day, we start seeing many more use-cases than just using resources continually. Using something like auto-scaling groups is another example. Auto-scaling, or elastic infrastructure, will allow for growth and reduction in the application load. Perhaps there are multiple machines that just don’t need to be there until the load is there. The ability to scale quickly with agility is enabled only through automation in either the cloud or on-premises.
Conclusion
Sterling is working around the clock to find solutions for our customers. I used to work at Circuit City as the Tech Lead — a modest resume item, but hear me out. Even there, the user-need I saw wasn’t for off-the-shelf machines but for the right components installed and configured. We had a group for this called “Firedog,” and the guys that ran that desk were some of the best technologists I’ve worked with. They didn’t know much about software, but they knew exactly how to set up hardware components based on each customer’s need. They verified that the parts hummed and maintained stability before delivery to the customer. At Sterling, our efficiency is very similar, especially in the current climate. We know we can get what our customers need and get it to them quickly. We do this while focusing on dependable vendors for each component but don’t lean on vendors alone to provide all the resources. We do what we can to fit pieces from multiple vendors to fill your orders more quickly.
If the solution isn’t found in hardware, Sterling’s services arm stands ready to check your environment, give a clear assessment of its usage, and advise on best practices. We might look through your virtualized environment to balance each cluster and verify that resources are used properly. We might examine your data usages and verify that hot storage stays local and is easy to access, while colder, un-needed storage is kept in the cloud with cheaper lower-speed storage. Perhaps we might automate solutions to scale in and out as resources are needed. This is where Sterling can help you use your resources smarter.
Finally, expanding into the cloud in multiple ways allows you to utilize resources already deployed to leverage them locally and deploy hybrid-cloud solutions that also extend your footprint. We will discuss that in a later blog in terms of expanding into the hybrid cloud for cloud migration or cloud extension. Keep your eye out for that coming soon!