By Nathan Bennett, Sterling Cloud Architect
If you’ve ever been the administrator of a local data center or a data center for a business, you understand what it’s like to continually have more and more piled onto your plate. In a former job, I often had to manage automation tools and workflows on top of developing pipelines for patches and updates to our core services, while at the same time being on an ‘on-call’ rotation and having to resolve databases going down. (That’s a lot to throw at specialists hired for their specific skills in specific areas.)
A result of the business-centric idea of “doing more with less” is that employees must frequently update their skill sets, take their knowledge to another level, try to keep up as the environment expands. A value proposition of the VMware product line is that it was developed by listening to customers and understanding what it’s like to manage and maintain more and more solutions. Usability, versatility, and reliability are regularly upgraded in VMware software’s core services, while granting that other quality every administrator needs: ease of use.
vSphere 7.0 U3 announced
There are many new features in vSphere 7.0 U3. I’ll hit a couple of highlights I think are unique. The updates that add new management, operation, and simplicity to vSphere are truly awesome. It all starts with the expansion of one of their newest solutions, vSphere with Tanzu. This amazing solution brings container-management and Kubernetes cluster-management into the purview of the administrator.
The first announcement I was extremely excited about involved something that had been an issue with Tanzu since its release: vague error messages. If you’ve ever run the workload-enablement workflow, you understand just how bad the error messages are. Many hours have been lost trying to troubleshoot generic messages like “An error has occurred and the process will be retried.”

Maybe it seems silly to be excited about something that should be so simple and universal, but those error message issues led to a lot of discussion and created real challenges working with Tanzu, leading many customers to simply state, “It’s not ready.” So, error-messages that lead to a specific issue that needs to be fixed will be very welcome.
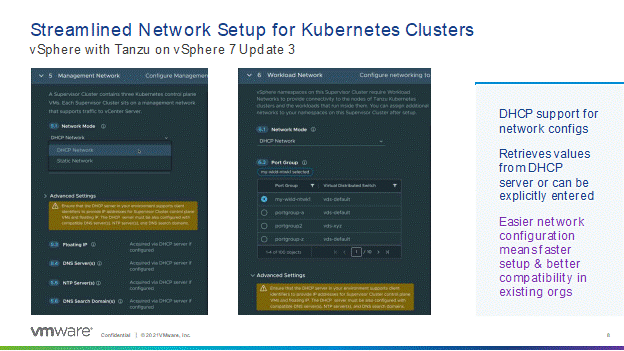
Another great feature, specifically for Tanzu, in this update is the ability to utilize DHCP protocol for workload enablement.The process to enable Tanzu has also been the culprit behind many late nights of troubleshooting the networking components to ensure the IP space is correct. However, with the new, updated settings, you should now simply specify the segments or port groups you will be utilizing, and it will set up the needed IP space via DHCP. I’m sure there will be some settings specifically for the DHCP component in terms of reservations to ensure these IPs are held by the clusters, but that information and the specifics will come out later.
Another unique solution in this update is the enablement of AI/ML workloads via an enterprise-grade solution to manage your workloads. This comes from the partnership with NVIDIA that started with Project Monterrey and will probably lead to many other developments in this space. It is worth mentioning that NVIDIA allows a direct-access link to their GPU solutions that allows intense AI/ML workloads to continually have the resources they want. This is different from VMware’s vSphere Bitfusion offerings, as Bitfusion works through the network and is a more dynamic solution to move resources freely between workloads. This versatility with the platform allows data scientists and IT admins to work in tandem, which is very similar to a Tanzu solution. I’m sure more about this will be announced during VMworld. Not to be out done, Bitfusion also has improvements, including faster APIs, control, and visibility, through their updating to Bitfusion 4, and the support it has via the vCenter 7.0U3 GUI.
Many other features have been announced, including the degradation of SD-Card/USB utilization for ESXi boot media: VMware are now starting to move to local storage, which will partition a segment that will be utilized for the storage. They also announced new lifecycle-manager capabilities for upgrades, VMC on AWS integration (to rebuild vCenters during their upgrades to remove downtime), full integration with Cloud-Init for guest OS configuration, PowerCLI 12.4, and more.
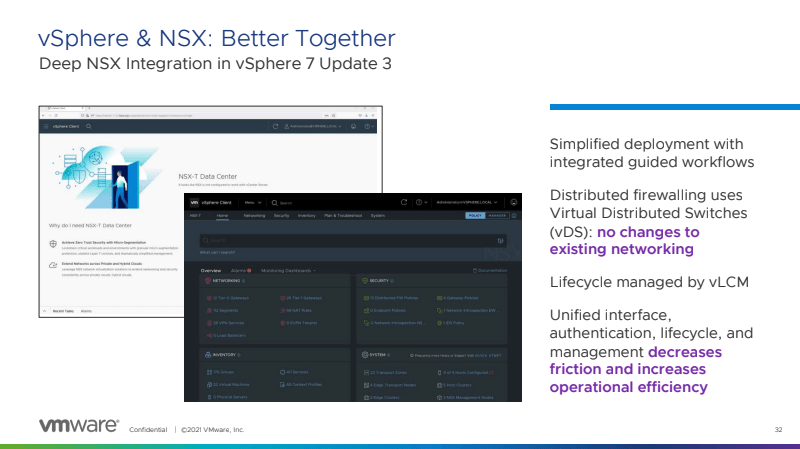
The last feature I’m personally excited about is something I saw a long time ago. VMware announced they will be bringing NSX-T configuration into the vCenter GUI. This will remove the continual back and forth between vCenter and NSX-T for configuration and verification. It’s a small change for some, but for power users who are utilizing NSX-T for all their integrations including Tanzu, it’s a pretty awesome addition.
vSAN 7.0 U3 announced
vSAN has been a staple of storage for VMware for a while now. It may have had a rocky start because of some requirements and best practices, but it’s a real gem these days. I’ve personally enjoyed the ease of setup for the solution: Tell it ‘what the capacity is’ and ‘what is in the cache drives,’ and it just goes. vSAN’s ease of use is why a lot of administrators within the VMware space can now say they are also storage administrators — because they suddenly have been told it’s their responsibility to manage it. vSAN makes this easy though, as its algorithms do most of the work for them, maintaining high availability, durability, and resiliency in its operations.
This new update of vSAN introduces features that vSAN can utilize to integrate storage with your workflows. This starts with Tanzu as it did with vSphere. The first announcement we heard was about the ability to move block-based storage into file-based storage within Tanzu workflows. This is more commonly referred to as Read-Write-Many (RWM) volumes that can be deployed within vSAN. Currently, most deployment schemas with Tanzu workloads are Read-Write-Once (RWO), but this brings RWM into vSan’s core storage-service.
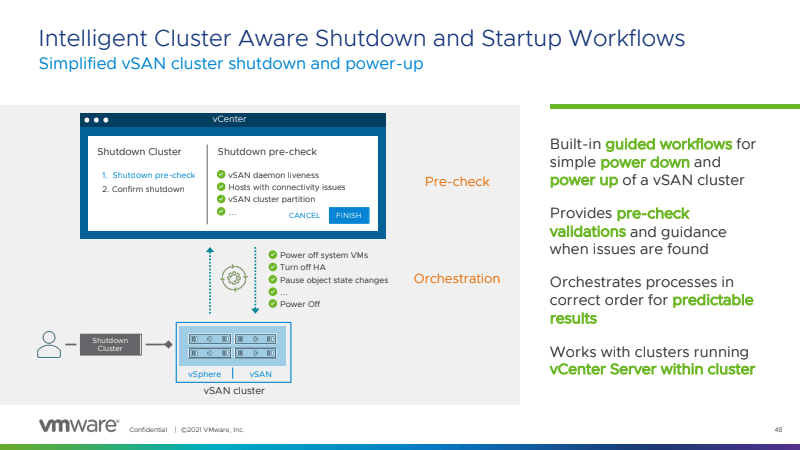
Another announcement I enjoyed hearing was that vSan added the workflows within vCenter to understand what should be powered down when shutting down a cluster. I’ve personally seen vSAN scramble multiple times in my home lab — because of power outages, or my kid unplugging something, or my simply not following best practices. This solution now ensures the automated takedown of the cluster, maintaining the storage necessary and bringing things down gracefully.
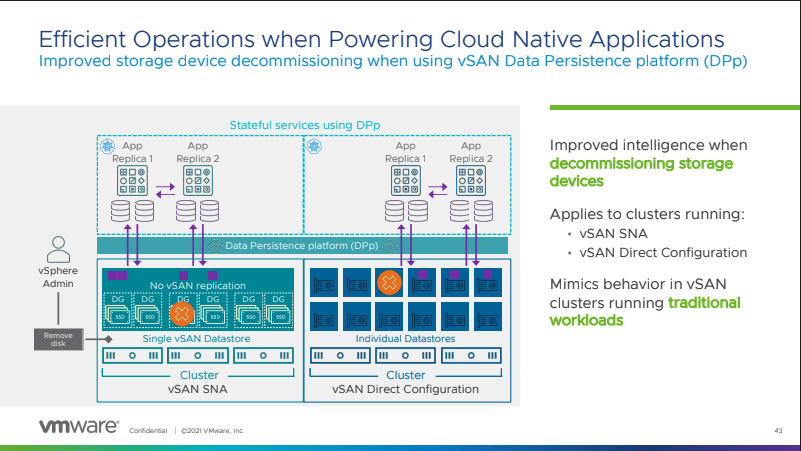
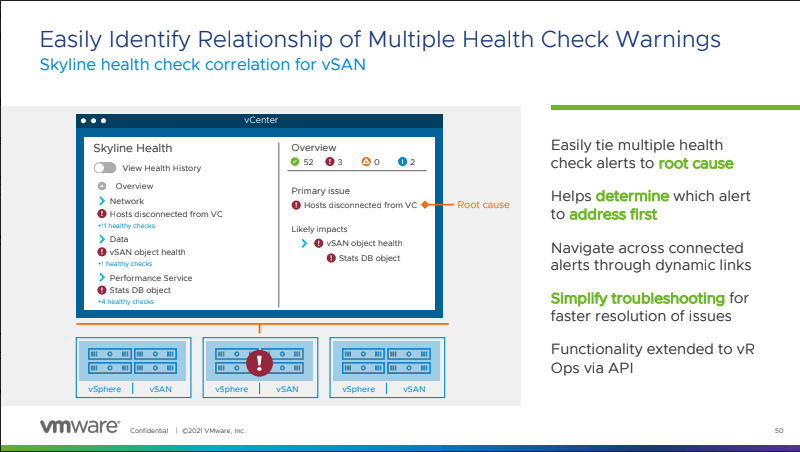
vSAN announcements seem to keep coming. VMware is de-coupling the enablement of MinIO and Cloudian workflows from vCenter. What this does, besides removing the enablement, is to remove the dependency. For example, if you want to update MinIO or Cloudian, you don’t have to update the full vCenter; instead, you can simply update these solutions independently. In the updated vSAN, stretched Kubernetes clusters can allow vSphere pods to be deployed within a cluster between two different vSAN clusters. VMware has also announced that they will be adding logic to the errors you will view within Skyline health check for vSAN. For instance, if there is an issue with a vSAN object, and that object is within a host, and that host is down, this update will give you a “primary issue” that dictates what should be addressed first. This clears up the confusion of multiple errors and allows you to focus on the specific issue that needs to be addressed.
I could write much more about features of this new update, and even more things will be in the announcement today — from improved uptime for stretched clusters, to more secure SMB file storage within vSAN. Also in this release: improved cloud-native monitoring to allow you to see your persistent volumes and understand the utilization of those objects within vCenter, improved cluster-network monitoring to say what layer may be having issues with the network, and more.
Conclusion
VMware maintains the pedigree of its core virtualization services. The issues that administrators face (e.g., doing more with less) are continually supported by the service integrations and upgrades that come from these updates. Even something seemingly silly like adding two interfaces into one can be a huge time savings for these individuals. It helps them understand what they need to do quickly and what to plan to do later. It allows them to focus on what is truly the issue, instead of looking through myriads of logs and spending hours upon hours to find the issue. Even for our developers and application leader — there is something to help improve their workflows and solutions. From the expansion of cloud-native storage to AI/ML integration for self-service clusters — the development groups will find a lot to enjoy when managing their workflows.
Sterling is keeping a close look at VMworld announcements. Stay tuned for more on VMworld!