Written by Nathan Bennett, Cloud Architect, Sterling
The debate about diversifying your backups or backing up to the cloud is really a discussion about whether to “put all of your eggs in one basket.”
I have already discussed how backups are an integral part of recovery after a cyberattack, in my Sterling blog on VCDR (VMware Cloud Disaster-Recovery). Backing up your environment is the first step for protection from ransomware, bad updates, bad patches, and many other bad things that can happen daily. In code we refer to backups as ‘versions,’ and each code version is held to a specific standard that, if not upheld, would need to be rolled back to stable versions from faulty ones.
When we look at backups and the orchestration, infrastructure, and automation needed to perform them, we must start by asking some very basic questions: “Where do these need to be stored?” “How long do we need to keep these backups? and “How often would we/do we use these backups?” Your answers will help determine your solution. The end goal here should not be just disaster recovery (DR). I believe that combining backups and DR creates a rather lukewarm solution and that you should probably look at each as an individual solution. However, some customers may use backup solutions as an extension of DR, and that’s where cloud backups come in.
When I was growing up, I loved saving my allowance. My biweekly one dollar allowed me to get a new Ninja Turtle every month or two. I was so excited. But each time I got my dollar, my mom and dad would urge me to deposit it into the bank. Of course, that never worked. All I could think about was the shiny new toy I would get once I reached the amount I needed. Each dollar I got, my mom would say the same thing: “Don’t put all your eggs in one basket.” (Good advice, but she didn’t know that I had stored each dollar in a secret place known only to me.) A long-winded story, but the analogy stands true as we investigate backups.
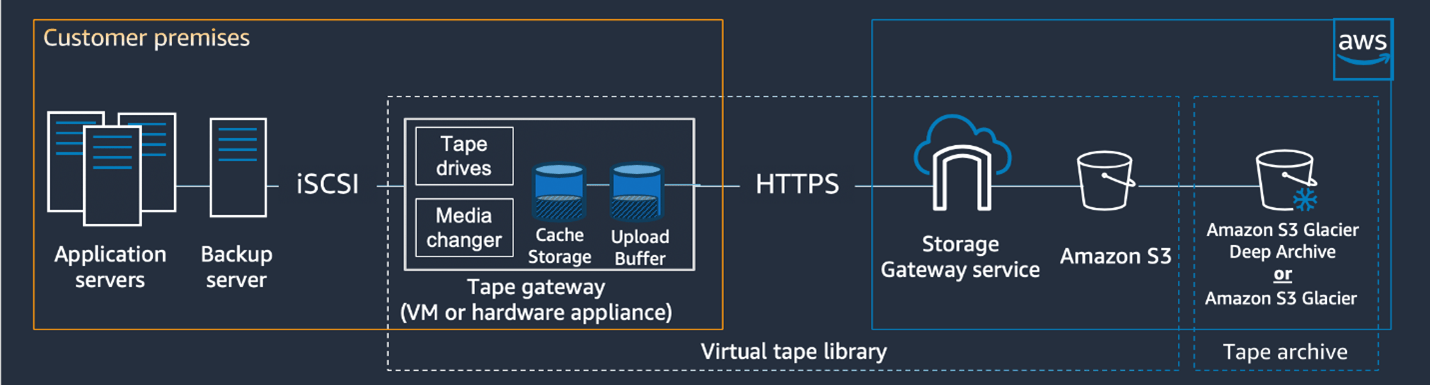 AWS Example
AWS Example
I cannot count how many times I’ve asked customers about their backup solutions, and their response is — a backup within a singular box located in their data center. I have already written about how horrible a solution this is — since the backups are all still within that single point of failure.
That a data center would be a single point of failure may seem strange to Operations and to the C-suite, who believe data centers “never go down,” but as we have seen from recent history — the ‘Snowpocalypse’ in Texas, the forest fires in California, and the random outages of edge-device fabrics that have brought down Amazon Web Services (AWS) data centers — the 99.9999 availability has never meant that it will never go down. A data center can and will go down, and this is based on AWS’s own framework. The AWS data center relies on outages, which is why they maintain the availability they do. What I mean by that is that AWS deliberately engineers failure into their architecture. They understand that each part of the cloud can and will fail, so they architect for it.
If AWS understands that everything will fail, then so should we. This leads to our next challenge, and my next story.
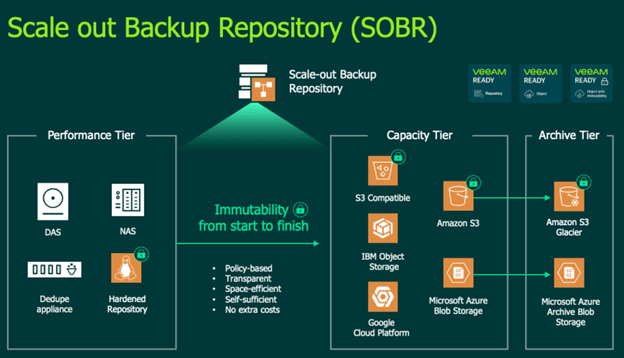 Veeam Example
Veeam Example
I enjoy movies, and a lot of my analogies come from cinema. The 2009 movie The Blind Side is a wonderful retelling of the true story of football player Michael Oher. The film’s title refers to a football quarterback’s greatest vulnerability — his “blind side.” Oher, as an offensive lineman, has the specific task of watching that blind spot and protecting the quarterback. Sandra Bullock, playing Oher’s mentor and adoptive mother Leeann Touhy, explains to him that NFL teams pay huge salaries to their quarterbacks, who, as team captains, call the plays and oversee the whole field. Oher’s position is the second-highest paid in NFL, because it protects that essential quarterback. “As every housewife knows—” says Bullock’s Touhy, “the first check goes to mortgage, the second goes to insurance.”
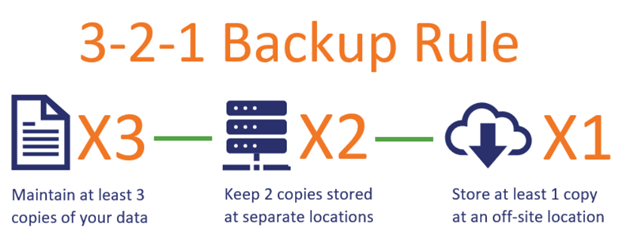
To me, that’s how backups and disaster recovery should be presented to architects and leadership within an enterprise. That is, the infrastructure holding the precious cargo (in our computing example, the application), will fail, and when it fails, you need a recovery solution that exists within backups. Monthly insurance bills cost a fraction of an amount; you do not pay the whole owed amount at once. And yet, the insurance will cover large repairs at any point. This same concept illustrates why VMWare’s VCDR becomes so competitive and such a powerful solution for businesses. However, if VCDR is not cost effective, which would possibly mean that co-location isn’t possible either, then what options are you left with? The last resort would be archival backups to cloud. This is commonly referred to as 3-2-1 backups (that is, three backups total: two on-premises and one in the cloud). When deploying 3-2-1 backup solutions, we focus too much on the two and not enough on the one and the three.
This is accomplished in many ways, but the most frequently used solution is within snapshot backup solutions, such as Dell IDPA, Cohesity, Rubrik, Veeam, etc. All of these have a component that pushes backups into cloud ‘object storage.’ What this means is those backups are sent to the cloud for pennies on the dollar, allowing that final ‘1’ backup to be kept outside of your on-premises solution.
I would like to be perfectly clear though that the above is not a disaster-recovery solution. What it does is keep backups outside of your local role-based access control and data center, helping to defend your data from failures both physical and sometimes virtual. This allows at its core the ability to restore solutions from months back, but also, in some cases, enables recovery from ransomware. By removing the local access from these backups, you add another level of deterrence to discovery and retrieval of these backups.
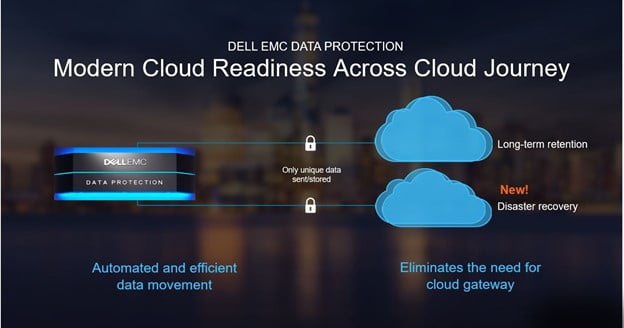 Using Dell Data Protection
Using Dell Data Protection
One last thought that I would bring up about this backup solution: It does allow some disaster recovery. Yes, I have said repeatedly that this is not a disaster-recovery solution, and I stand by that assertion, because doing DR with archive backups is bad for multiple reasons. First, you are recovering at least a month behind your past infrastructure. Second, you must be able to tolerate a very long recovery period that is far beyond what enterprise businesses should understand to be disaster recovery. Third and finally, you need to be able to import the backups that are archived and restore them into some different location, be it in the cloud or another on-premises location. For example, with Veeam, you can simply re-deploy Veeam Backup and Recovery and connect it to the same backup location, and that will import those backup files. Once Veeam B&R has that insight into the cloud object store, you can then restore the backups into cloud-based infrastructure including AWS, Azure, and GCP, depending on the solution you utilized for your backup. Disaster Recovery is one aspect of keeping a business rolling when there is a full-on disaster or a ransomware attack. Unfortunately, sometimes ransomware is able to find and corrupt your DR solution, which is when archival DR may be a next option.
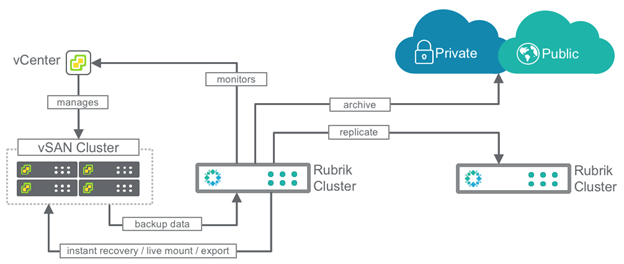 Rubrik Example
Rubrik Example
If you are interested in learning more about archival backups and how certain procedures can help deter ransomware, preserving your environment through outages, contact Sterling. Sterling excels at filling in the gaps about what can be done, offering demos and discussions that show backups which can be performed and what we can do to help you through the steps. Finally, if you do need additional support for recovery operations, we can help clear the fog and clarify the steps needed to perform these tasks, as well as test them as you look at each backup solution for your environment.