Written By Billy Downing
What is a Cloud Native Application?
Cloud native application development is the method of breaking down workloads into business logic processes which can then be abstracted from infrastructure, observed with granularity, and deployed rapidly. This does not necessarily mean cloud native applications are required to run as thousands of microservices on a Kubernetes cluster, nor does it even require the applications to be containerized. However, these methods of software packaging and orchestration do facilitate workloads to become separated from their underlying infrastructure and ran anywhere so long as the agreed upon open standards are adhered to. Containerized applications being orchestrated through Kubernetes allows workloads to be quickly deployed in several environments including public clouds, private clouds, and hybrid architectures while affording control of the application environment to the developer (segregation through network policies and namespaces, load balancing through ingress and services, dynamic storage provisioning through class and persistent volume claims, etc). For a clear picture of Cloud Native check out the CNCF definition as well at https://github.com/cncf/toc/blob/master/DEFINITION.md
What is the Cloud, and why should our applications live there?
NIST Defines the five key attributes of a cloud as On-demand self-service, Broad network access, Resource pooling, Rapid elasticity, and Measured Service (https://csrc.nist.gov/projects/cloud-computing) These characteristics do not define location or tool sets, however do provide the functional requirements of what is necessary to deploy a cloud environment. In the situation of cloud native application development on-prem it becomes the responsibility of the operations team to deploy these attributes in an environment from the perspective of the developer. The developer must have the means for on-demand self-service in provisioning infrastructure to support and deploy their software, with the remaining attributes handled for them without intervention. This provides the benefit of focusing on the business logic of the application and less emphasis on the underlying infrastructure. However, in order for the support components to become sufficiently abstracted away a few things must happen:
- The infrastructure needs to be definable by software.
- The instantiation of all components must be automated.
- All components must be treated like cattle, not pets.
- Application packaging must have the means to include a description of the necessary environment.
With the stage set, how do we accomplish this on-prem?
While there are hundreds of tools to accomplish this (just take a look at the CNCF Landscape https://landscape.cncf.io/) here are the list of tools and platforms we’ll be going through to realize the on-prem cloud environment.
- Enterprise PKS for automated Kubernetes cluster provisioning and life cycle management
- Kubernetes for container orchestration
- Docker as the container run time
- ESXi/vSphere for virtualized compute
- NSX-T for virtualized networking
- GitLab as a code repository & GitLab CI for a defined pipeline to rapidly test and provision code
- Harbor for the image repository
- vRealize Operations Manager, Network Insight, and LogInsight for observation
These tools will be tied together to provide an entire application pipeline as describe here:
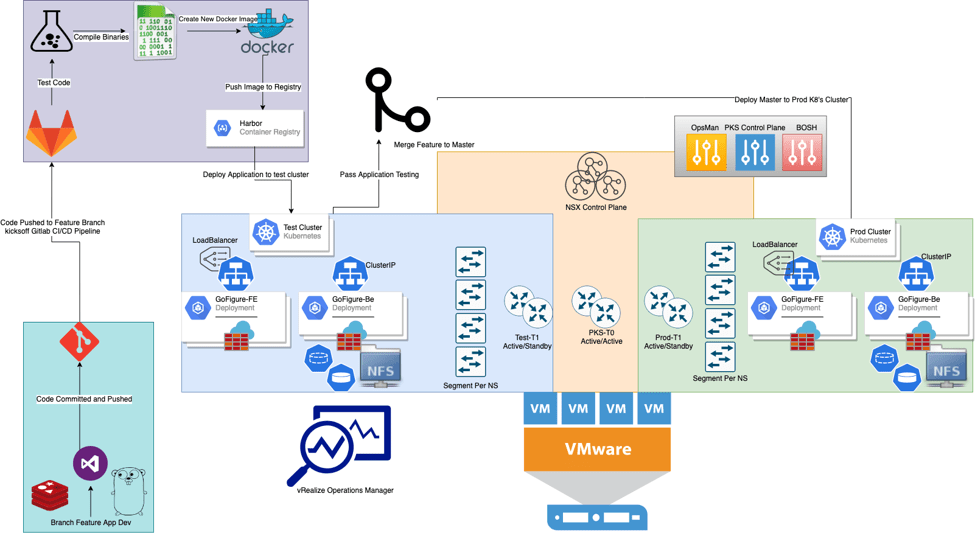
Process Flow
- Developer makes changes, adds files, commits code, and git pushes to Dev branch hosted on local GitLab server
- GitLab kicks off GitLab CI and begins pipeline process using dedicated GitLab Runner
- Compile binaries, run code tests, verify grammar and syntax
- Create new docker images based on changed code
- New binaries and new static files built into image
- Push newly built image to local Harbor Image Registry
- Create a test environment using Enterprise PKS to deploy and further test application
- Enterprise PKS will instantiate an entire cluster based on the same plan as production
- This will coincide with all required objects being built in NSX-T
- Once Enterprise PKS successfully created test-cluster, deploy k8’s deployment manifest tagging all pods with scope: env tag: dev.
- With the application up and running in a test-cluster, conduct further application testing
- In this case, a simple ‘curl’ to the LoadBalancer type service to ensure web services are responding is sufficient
- If tests are passed, this portion of the pipeline is complete.
- Submit a merge request within GitLab to merge the tested dev branch into master
- Once merge request is approved, second pipeline kicks off to conduct a rolling upgrade of the prod-cluster to pull down the new version of the application containers.
- Once the new version of the application has been merged to master and deployed to the prod-cluster, the pipeline will continue to destroy all test-cluster artifacts to free-up any remaining resources
- Pipeline is complete, change has been successfully tested and deployed to production with minimal intervention
Overall, in subsequent posts we’ll describe how the use of these individual tools and platforms together, on a per-product basis, provide an on-demand, elastic, and always available infrastructure to support the rapid development of applications in a private cloud using a real-world example digging deeper into each phase of this flow.