Written By Billy Downing
What are Containers and why are they synonymous with Cloud Native Applications?
Containers are packaged software which include all dependencies while providing abstraction from underlying infrastructure. Containers sound similar to virtual machines with a distinct difference in where the abstraction occurs. Within virtual machines, hardware is virtualized and presented to the software unit as consumable resources, whereas with containers only the underlying operating system (the kernel) is virtualized and abstracted. This provides the benefit of allowing the software within a container to use resources provided by its host kernel removing any dependency on hardware. Typically, containers adhere to a one to one ratio of processes per container, therefore breaking up an application into a series of independent containers defining each process becomes a natural design principle when compared to developing applications in many processes per virtual machine as previously done.
- Containers abstract application dependencies
- Virtual Machines abstract hardware dependencies
So why are containers associated with Cloud Native Applications? Based on the principles of one process per container and containers only abreacting the application components necessary to run, containers provide the benefit of striping away all unnecessary components in order to run (I.E, operating system and associated drivers) which make them extremely portable, resilient to failure from an application perspective as each container (process) runs independently in a distributed system, and if done correctly less resource intensive. However, in a container environment where many processes used to be associated with a single virtual machine, now each process is broken into an individual container which in some cases lead to much higher management overhead to orchestrate and tie everything together. In comes Kubernetes.
10,000 Foot View of Kubernetes
Now that each process of our code is packaged with all of its dependencies within a container and subsequently causing an explosion of individual processes acting as the base unit of the application as a whole we need a way to schedule, run, network, provide storage to, and lifecycle our application. Kubernetes utilizing a master/worker, pluggable, architecture provides a means to standardize the deployment, management, and optimization of container-based workloads (and other workloads, for that matter). Applications typically consist of more than just business-logic and for-loops, requiring infrastructure to serve functionality. In a traditional environment each component used to server the application is not packaged directly, but provides as a service to the application, such as load balancers, proxies, network overlays, persistent storage and so forth. Kubernetes provides a set of standard APIs to adhere to in order to package not only the applications themselves into a deployment, but also the necessary infrastructure as well. By using constructs such as Container Network Interface (CNI) or Container Storage Interface (CSI) vendors are able to translate Kubernetes manifests into tangible infrastructure to support the application environment. This allows software to be directly tied to the infrastructure required to run it.
For example, VMware NSX-T running alongside Kubernetes using the NSX Container Plug-in (NCP) provides the benefit of dynamically translating ingress controller objects into functioning layer 7 load balancers, namespaces into overlay segments, and network policies into distributed firewall rules. All of these components can be packaged, scheduled, and managed using Kubernetes as the lifecycle orchestrator.
Who Orchestrates the Orchestrator? In comes Enterprise Pivotal Container Service (PKS)
At this point we have our application broken down into a set of distinct processes, or services, packaged nice and neat into containers, and running safe and sound managed by Kubernetes along with all its software defined infrastructure needs. Cloud Native Applications require the ability of elasticity, which can be accomplished by Kubernetes spinning up more containers as load increase. However, say for example in your environment there are three master nodes and three worker nodes where the three worker nodes are running all the application containers. If a container halts or stops running, Kubernetes will terminate is a deploy a new one, if a service becomes overwhelmed with load Kubernetes will schedule more containers to run behind it to distribute the traffic. However, what happens when the worker node itself becomes unresponsive, or load increases to a point where resources are contained? In our scenario, we utilize an orchestrator for the orchestrator, specifically Pivotal Container Service (PKS) employing BOSH to manage and maintain the actual Kubernetes cluster running our workloads. Much like what Kubernetes is to our applications, BOSH is to our Kubernetes clusters. BOSH, using the concept of deployments, manages the underlying infrastructure of a Kubernetes cluster by monitoring and maintaining the lifecycle of the masters and workers themselves. If nodes become unresponsive, BOSH will reengage and redeploy the impacted node. If worker nodes become overwhelmed with traffic, BOSH can be used to increase the amount of worker nodes within the deployment. Overall, as Kubernetes provides the elasticity within the container environment BOSH provides the elasticity for the cluster as a whole.
How Does Enterprise PKS Do it?
PKS is made up of several components each of which providing the service of life cycle managing the platform for which to service cloud native applications.
- OpsMan
- OpsMans is the glue for PKS. OpsMan provides the means for initial deployment, interface for PKS infrastructure management (upgrade to bosh/pks control-place), and the deployment of infrastructure configurations. OpsMan manages components each tied to a tile.
- PKS Control Plane
- The PKS Control-Plane provides the API endpoint for which all Kubernetes cluster actions are invoked. PKS Control-plane is where Kubernetes specifications, or plans, are defined (I.E, how many master or worker nodes, logging, CSI and CNI parameters, ect). When deploying a PKS controlled Kubernetes Cluster, PKS control-plane is responsible for provided the necessary configurations and translation of API calls to BOSH deployments.
- BOSH
- Bosh is the lifecycle manager for all the components within the system, including all master and worker Kubernetes nodes. As clusters are requested through the PKS control-plane, Bosh physically deploys, bootstraps, and configures all nodes required to satisfy the PKS plan.
What Benefit Does Enterprise PKS Provide?
The burning question comes down to what value does Enterprise PKS bring to the table. Building, scaling, maintaining, and deleting production ready Kubernetes clusters is no trivial task. A typical environment will include several independent Kubernetes clusters in order to support development needs either a cluster per use-case (dev, test, prod), per application, or somewhere in between. Enterprise PKS provides a uniform deployment strategy for Kubernetes clusters across private and public clouds alike thereby reducing the management complexity and deployment time for production Kubernetes with any associated services (Image registry, lifecycle management, logging, NSX-T integration, etc.). Beyond deployment and scale, Enterprise PKS also sits around for Day 2 and beyond operations such as upgrading Kubernetes clusters, instantiating new nodes during times of failure, and deploying new services as daemon sets as needed.
Visualize the Solution
Let’s take a look at the actual infrastructure as it’s deployed by Enterprise PKS in order to support Production ready Kubernetes clusters.
Figure 1 displays the perspective from the OpsMan console, which as mentioned provides the glue for the Enterprise PKS deployment. Within this console we see three tiles reflecting our deployment, one for BOSH, another for the Enterprise PKS Control-Plan, and finally our Harbor Image Registry which we’ll discuss in a follow-on post. From this console platform engineers can manage the lifecycle of the infrastructure components for PKS, as well as configure Kubernetes cluster plans deployed, certificate registrations, and resources utilized.
 Figure 1
Figure 1
Each tile within OpsMan represents the actual entity deployed as a virtual machine, shown in figure 2. As deployed by OpsMan/BOSH the VM’s will have a UUID as the name which can be later correlated to BOSH deployments and cluster attribute tags. Within Figure 2, we have three resource pools. AZ-1, AZ-2, and Mgmt. In this scenario, AZ-1 and AZ-2 host separate Kubernetes clusters (prod-cluster and test-cluster) hosting a single master and single worker each. Within the Mgmt resource pool we have the OpsMan, PKS Console (used to deploy the solution), BOSH (vm-067…), Harbor (vm-48a…), and Enterprise PKS Control (vm-cfc…). Each of these components reside on a overlay segment provided by NSX-T as well.
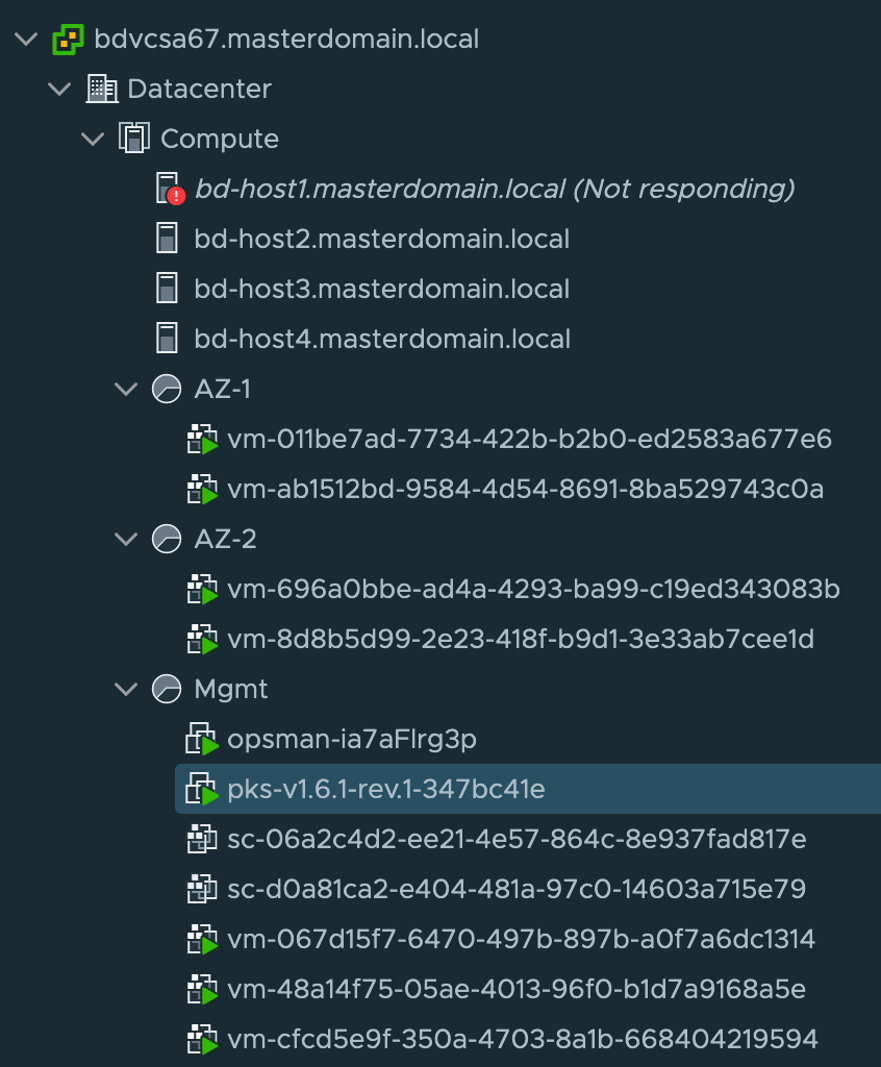 Figure 2
Figure 2
That takes care of the infrastructure side supporting our K8’s clusters, now let’s see what they look like from the Enterprise PKS perspective. In figure 3 I’ve shown the two clusters established and created by BOSH instantiated through Enterprise PKS and the details of the prod-cluster giving the kubeAPI URL, IP address which was dynamically pulled from an IP Pool from within NSX-T, the Kubernetes version, number of worker nodes, and last action status.
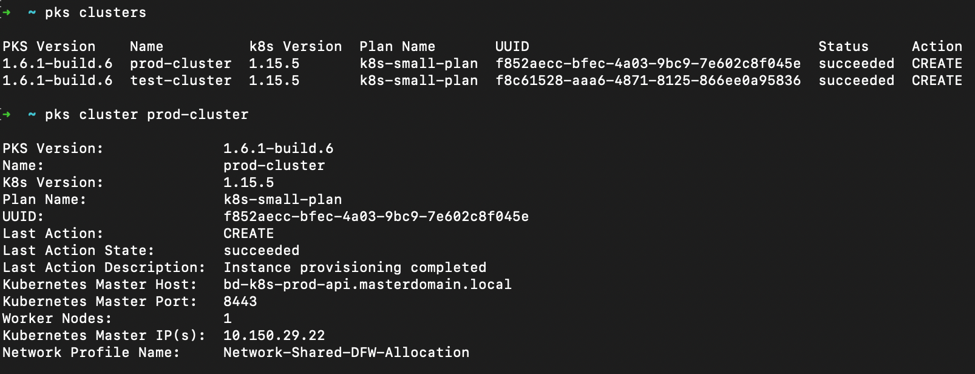 Figure 3
Figure 3
Now from the BOSH perspective we can see in figure 4 each individual node within the deployment (matching the UUID from the PKS Cluster to the Service UUID in the BOSH Deployment), as well as the services which were instantiated based on the Enterprise PKS Plan, internal IP’s, and availability zone location. This view provides insight on the depth of monitoring BOSH provides for a K8’s cluster as well as the various services (such as NCP for NSX-T integration, Fluentd for logging, dns, healthchecks, etc) that are added to the K8’s deployment for better management and added features.
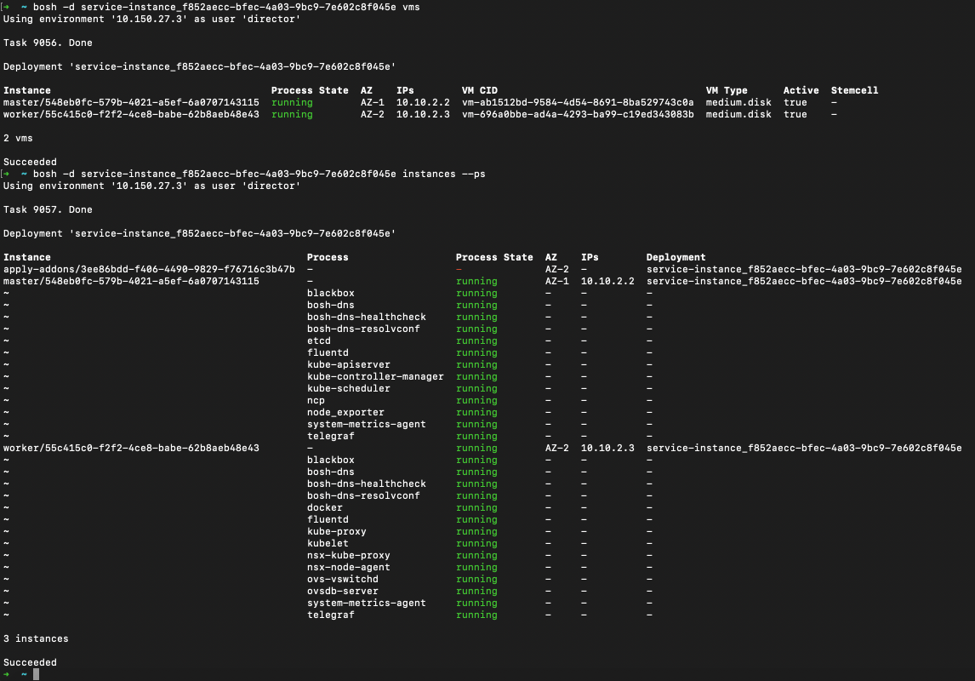 Figure 4
Figure 4
Finally, in Figure 5 we can evaluate the actual workloads running on the deployed k8’s prod-cluster. First by grabbing the credentials, or kubeconfig, through the PKS API, then by using the familiar kubectl command line tool. The output of pods displays not only the application deployed (gofigure), but also all the other management related pods deployed as part of the Enterprise PKS standard build based on the configure plan.
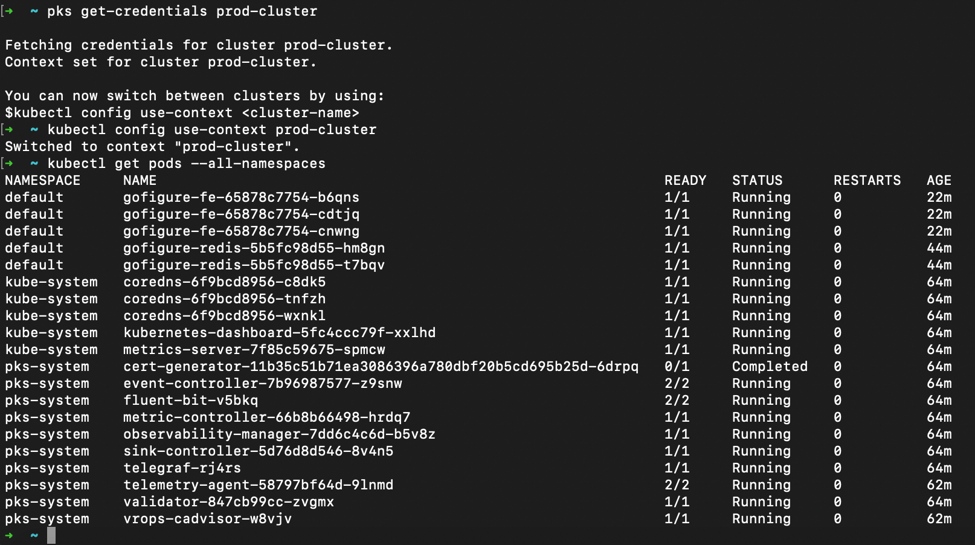 Figure 5
Figure 5
Coming Full Circle
With the basis of our pipeline, depicted below in Figure 6, Enterprise PKS supports the creation and management of our elastic Kubernetes environments for test and prod giving us more time to focus on what matters, the business logic within the application itself.
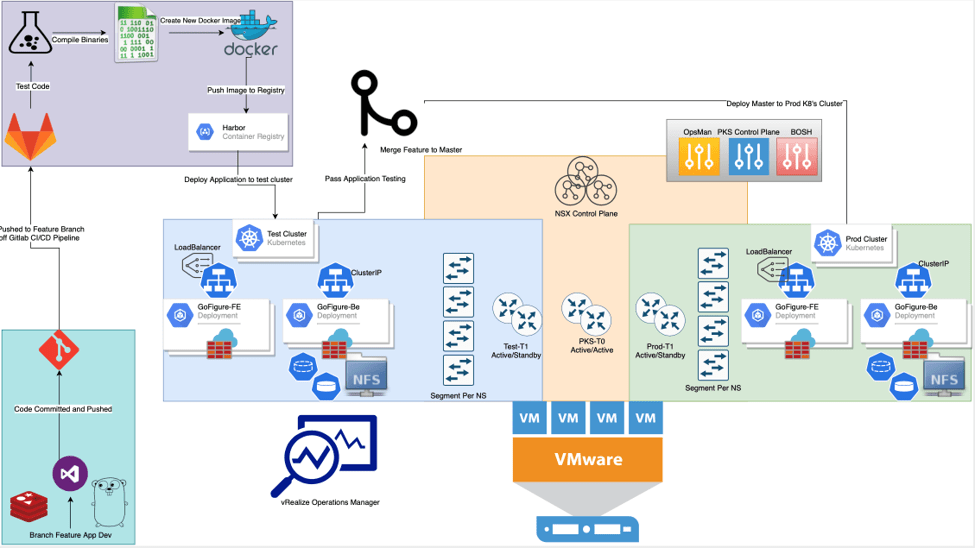 Figure 6
Figure 6